
좋은 협업자가 되려면 어떻게 해야 할까요? 좋은 협업은 뭘까요?
정답은 없겠지만, 제가 겪은 시행착오와 그에 비롯한 생각들을 적어봅니다.
시작
좋은 협업이 무엇일까요?
꽤 질문이 추상적이고 저마다의 가치관과 이해 관계자에 따라 달라지기에 쉽게 대답하기 어려운 문제인것 같아요.
개발자 간에 좋은 협업으로 한정하여 말하자면, 저는 특정 기능을 구현하기 위해 왜 이렇게 코드를 작성했는지 설득하고 상대방이 작성한 코드를 이해하기 위해 노력하는 커뮤니케이션이 원활히 동작하는 상황이 좋은 협업이라고 생각합니다.
이번 글은 전자인 왜 이렇게 코드를 작성했는지 설득 하는 단계에 초점을 맞췄는데요.
제 의도를 이해시키기 위해서 했던 저의 시행착오들을 회고해보고 더 나은 방향으로 생각하는 점들을 적어보겠습니다.
Git Commit
어떤 집단에 속해있던, 다수의 인원이 하나의 프로젝트를 빌드한다면 git 을 사용하고 있을겁니다.
Local Branch 에서 기능 구현 => Pull Request Review => Remote Main Branch 에 Merge 하는 절차를 다들 밟고 있을텐데요.
이 Pull Request Review 의 단계에서 혹시 아래와 같은 경험을 하신 적이 없으신가요?
A 는 +1,123 -193 의 diff 를 가진 B의 Pull Request 를 Review 해야합니다. File Changed 를 열심히 들여다 보지만, 해당 코드가 무엇을 뜻하는지 모르겠어요.
'B가 어련히 잘 했겠지' 라는 생각으로 신뢰의 approve 를 합니다. B는 내가 짠 코드에 결함이 없는지 불안하여 리뷰를 원했는데, LGTM 이란 하나의 코멘트와 함께 Pull Request 가 Close 되었습니다.
다들 한번쯤은 A 혹은 B 가 되어본 경험이 있을거예요. 보통 이와 같은 상황은 누가 잘못한 것이라 생각하시나요?
아마 다들 리뷰를 대충 한 A 를 탓할 것 같습니다. 저도 그래요. 특정 코드가 무슨 의미인지 모르겠으면 물어봤어야죠.
그러나, B도 과실이 있다고 생각해요. 특히 불안한 Pull Request 라면, A 가 잘 이해할 수 있도록 여러 장치를 해두어야 한다고 생각해요.
그렇다면 어떤 장치를 시도해 볼 수 있을까요?
Git Commit Message
제가 정말 존경하는 개발자님에게 이런 질문을 한 적이 있습니다.
제한된 시간 내에 빠른 구현을 위해 어떻게 해야 할까요?
그 개발자님은 특정 기능을 구현할 때 코드가 아닌 커밋 메시지를 미리 작성해본다고 하셨어요. 그리고 해당 커밋 메시지마다 특정 파일의 어떤 부분을 수정해야 할지 청사진을 그려놓고 그제서야 코드를 작성한다고 하셨어요.
전 크게 공감을 했습니다. 코드의 작성에 앞서, 이런 절차를 거치면 이 기능이 구현될 거야 란 설득을 스스로 할 수 있어야 한다고 생각해요.
Pull Request Review 도 비슷하다고 생각합니다. 결국 상대방에게 이런 절차를 거치면 이 기능이 구현이 돼 라는 설득을 하고 이를 검증하는 단계입니다. 그리고 이 절차를 나타내는 것이 커밋 이라고 생각합니다.
코드를 읽는 입장에선 상대방이 작성한 코드에 대해 얕게 알고 있을 수 밖에 없습니다. 그래서 절차가 나눠져 있지 않으면 이해하는 데 많은 시간을 소요해야하고, 규모가 거대해질수록 이는 기하 급수적으로 늘어납니다. 커밋이 잘 나눠져 있다면 절차를 파악하며 상대방의 의도를 보다 더 잘 파악할 수 있습니다.
리뷰를 바라고 만든 Pull Request 는 아니라 좋은 예는 아니지만, 제가 작업했던 PR 의 Files Changed 와 Commits 를 비교해보겠습니다.
Files Changed
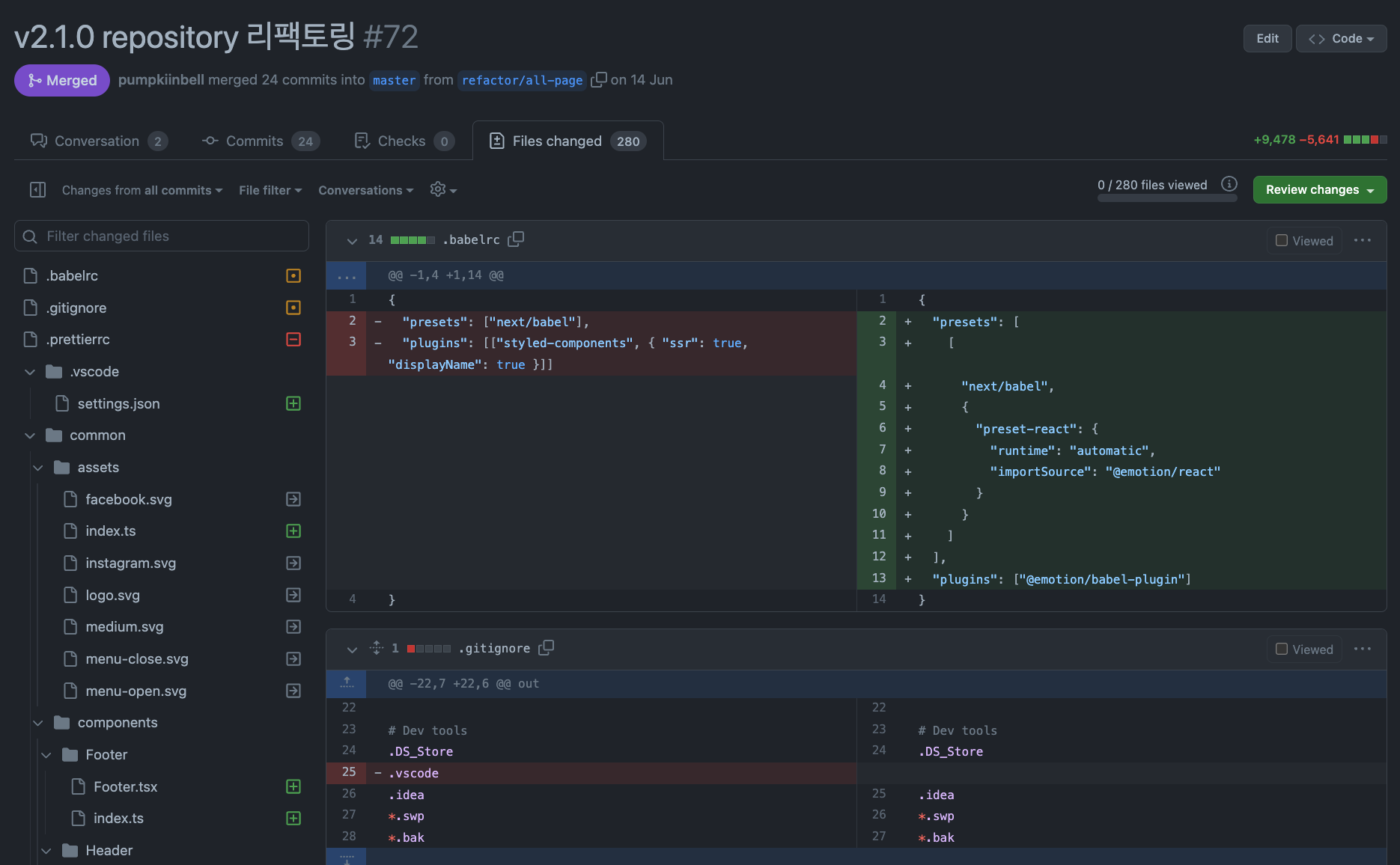
정말 거대한 리팩토링이었습니다. +9,478 -5,641 의 diff 를 가진 PR 이었어요.
이를 Files Changed 탭에서만 보면서 리뷰한다고 하면 이 코드가 무엇을 뜻하는지 잘 파악이 안될거예요.
잘해봐야 사소한 문법 오류, 네이밍 관련 코멘트를 남길 것 같습니다.
Commits
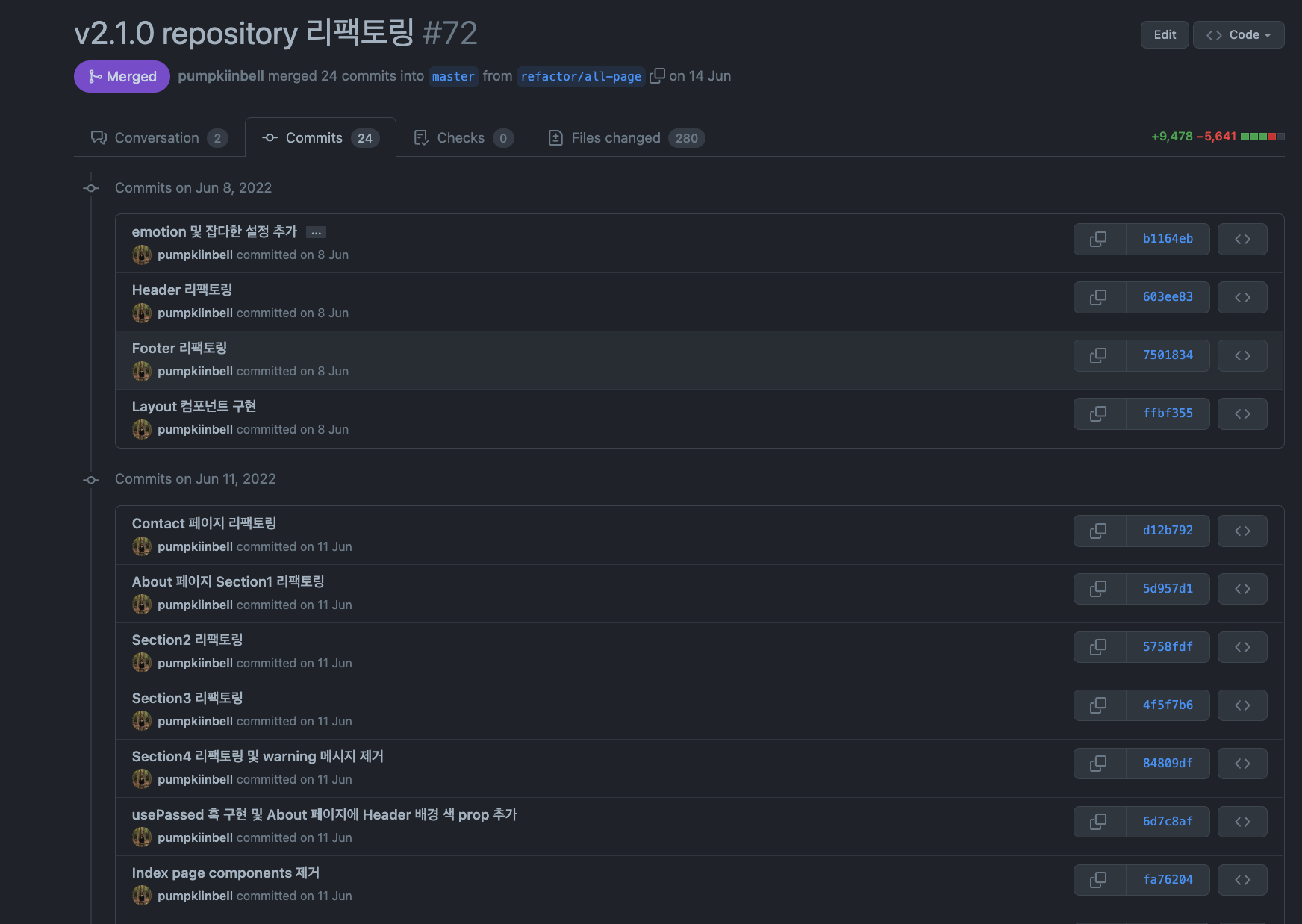
Commits 를 보면 어떤가요? 해당 PR 이 어떤 절차를 가졌는지 알 수 있습니다.
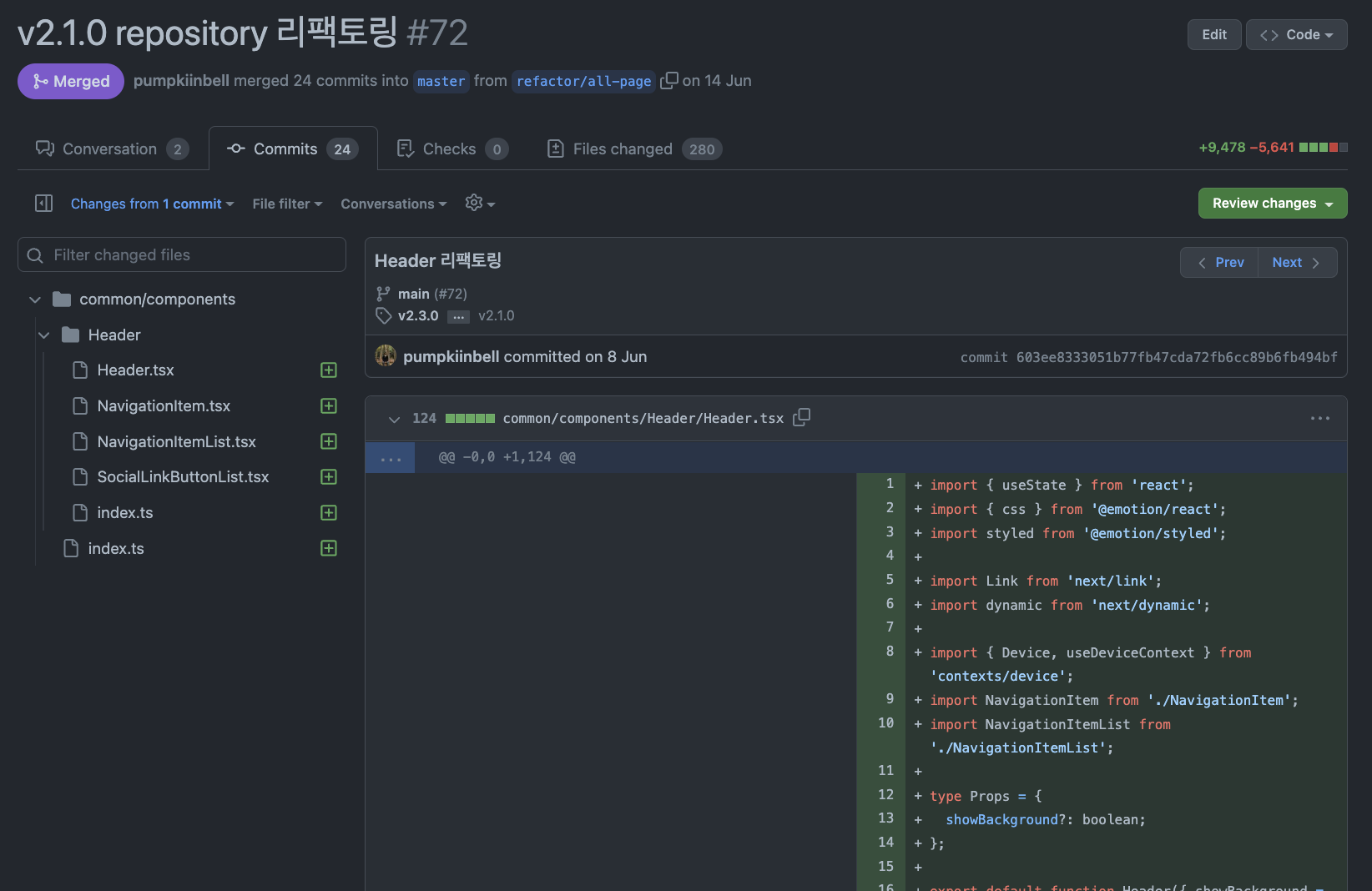
Commit Hash 를 클릭하면 해당 Commit 에 작성한 코드가 어떤 의미인지 쉽게 파악할 수 있습니다.
가령, 위에 보이는 예시는 Header 컴포넌트를 리팩토링을 하였으며 이를 위해 어떤 코드를 작성했는지 알 수 있습니다.
만약 내가 구현했다면 Header 를 어떻게 리팩토링 했을지 생각해보면서, 더 좋은 방향이 있으면 이를 리뷰하는 방향으로 진행할 수 있습니다.
Github 의 Commit 페이지에선 P / N 단축키로 이전 / 다음 커밋으로 쉽게 넘어갈 수 있습니다. 한영키에 주의해서 입력해보세요.
이렇기에 Commit 은 정말 중요한 역할을 한다고 생각합니다. 그렇다면 커밋을 어떻게 나눠야 할까요?
팀마다 있는 Grould Rule 을 우선적으로 고려해야겠지만, 큰 제약 사항이 없다면 저는 기능보단, 의미에 초점을 맞춘다. 라는 기준으로 커밋을 만듭니다.
로컬 브랜치에선 커밋을 checkout 할 시 정상적으로 동작하지 않더라도 하나의 의미로서 기능하는 커밋을 만드는 편입니다.
(main 혹은 master 로 합쳐지는 커밋의 경우는 다른데요. 후술할 Squash Merge 에서 다시 언급하겠습니다.)
저는 다음과 같은 방식으로 커밋 히스토리를 관리합니다.
- 만든 커밋에 오탈자가 있어 수정해야 할 경우, 추가적인 커밋을 작성하는 것보단 해당 커밋을 amend 하는 것을 선호합니다.
- Commit 의 의미가 옅은 경우 다른 커밋과 squash 합니다. 참고
- Commit Message 는 최대한 의미를 잘 드러낼 수 있게 단순하게 작성합니다. 대부분 한글로 작성하며 🐞 같은 emoji 는 의미 전달을 방해한다고 생각하여 선호하지 않습니다.
Squash Merge
앞서 저는 의미로서 기능할 수 있는 커밋을 선호한다고 하였습니다.
그러나 remote 의 main 혹은 master 에 합쳐지는 커밋은 다릅니다.
이들은 의미가 주가 되는 커밋이 아닌, 기능이 주가 되는 커밋이 되어야 한다고 생각합니다.
즉, checkout 시에 정상적으로 동작할 수 있는 커밋이어야 합니다.
다른 사람들이 기능 테스트를 위해 특정 커밋에서 checkout 을 할 수 있기 때문이죠.
이 때문에 저는 Squash Merge 를 선호합니다.
git merge 명령어는 squash 란 옵션을 지정할 수 있는데요.
squash merge 를 하게 되면 작성했던 커밋들을 하나의 메시지를 가진 커밋으로 묶어줍니다.
이로서 main 역할을 하는 브랜치에는 온전히 하나의 기능을 하는 커밋으로 구성할 수 있습니다.
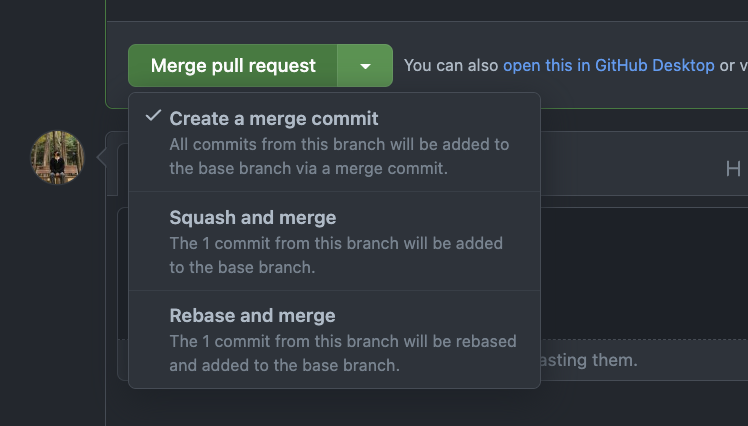
Github 에선 Merge Pull Request 버튼의 화살표를 클릭 시 옵션을 지정할 수 있으며,
Repository 설정 창에선 Squash Merge 를 디폴트로 설정할 수도 있습니다.
코드
앞서 git commit 과 관련한 많은 이야기를 하였으니, 이번엔 그 commit 을 구성하는 코드에 대해 이야기 해볼까 합니다.
제가 작성한 코드를 잘 이해할 수 있게 하려면 어떻게 해야할까요?
저마다의 의견이 다를거라고 생각합니다. 저도 개발을 하며 조금씩 계속 변하고 있는데요. 지금 시점에서 회고해 보았을 때는 아래와 같이 생각하고 있습니다.
Short Term Memory
Short Term Memory 란 단어가 있습니다.
사람은 처음 보는 내용은 Short Term Memory (이하 STM) 에 보관하고, 반복 학습을 통해 이 내용은 Long Term Memory 로 넘어간다는 것인데요.
재밌는 점은 STM 의 크기엔 제한이 있고, 기억할 수 있는 항목의 최대치는 12개를 넘지 않는다는 것입니다. 이 또한 숙련자가 그렇고, 일반적으로 2 ~ 6개 사이의 용량을 가진다고 합니다. 참고 - 프로그래머의 뇌
그러면 상대방이 이 용량을 덜 사용하게 코드를 작성하면, 상대방이 내 코드를 더 잘 이해할 수 있지 않을까요? 이 용량을 덜 사용하게 만드려면 어떻게 해야 할까요?
같은 문맥이라면, 해당 문맥을 유지할 수 있도록 해야 합니다.
dot notation
이전에 다음과 같은 코드를 작성한 적이 있습니다.
const {
payload: { type, name, ~~~ }
} = useFormContext();
// ~~~
type === 'a' ? doA() : doSomething();
type 이라는 식별자가 여러 곳에서 사용하고 있었고, 더 짧은 네이밍이 의미를 더 잘 전달한다고 생각했기 때문입니다. 근데, 오히려 destructure 를 안하는 것이 이해하기 편할 것 같다는 리뷰를 받았습니다.
- const {
- payload: { type, name, ~~~ }
- } = useFormContext();
+ const { payload } = useFormContext();
- type === 'a' ? doA() : doSomething();
+ payload.type === 'a' ? doA() : doSomething();
전자의 경우, type 이 어디서 유래된 것인지 파악해야 하고, 이를 위해 type 은 payload 에서 destructure 되었다. 라는 특징을 기억해야 합니다.
그러나 후자는 이미 payload.type 에서 이를 유추할 수 있기 때문에, 이를 기억할 필요가 없습니다. 물론 여러 번의 dot notation chaining 을 하게 되면 이 또한 기억을 해야겠지만, 특별한 경우를 제외하면 하나의 식별자를 위해서 destructure 를 하지 않으려고 합니다.
많은 지식들
어느 정도 합의되어 있는 내용을 많이 활용하면 STM 을 차지하지 않아도 됩니다. 이미 상대방의 Long Term Memory 에 해당 내용이 있기 때문이죠!
가령, 다음과 같은 코드가 있다고 가정해봅시다.
if (a == null) {
return undefined;
} else if (a.b == null) {
return undefined;
} else {
return a.b.c;
}
이는 optional chaining 으로 대체할 수 있습니다.
return a?.b?.c;
일상 생활에서도 많은 단어를 알면 특정 상황에 대한 장황한 묘사 없이 한 단어로 설명이 가능합니다. 코딩 또한 다양한 API 나 operator 를 알고 이를 적재 적소에 활용할 시엔 보다 가독성 높은 코드를 만들 수 있다고 생각합니다.
다른 문맥이라면, 확실히 chunking 할 수 있도록 해야 합니다.
Hooks, Components
컴포넌트를 작성하다보면 내부에서 여러 상태를 선언하고, 그 상태에 의존하는 Side Effect 로직들을 많이 작성해야 하는 경우가 많은데요. 이런 경우 코드를 읽는 입장에서 각 State, Side Effect 로직을 기억해야 하기 때문에 STM 를 많이 소모할 수 밖에 없습니다.
예를 들면, 다음과 같은 코드입니다. (설명을 위한 예시이므로 의사 코드로서 봐주시면 감사하겠습니다.)
function ProductListPage() {
const [productList, setProductList] = useState([]);
const [loading, setLoading] = useState(false);
const [error, setError] = useState();
const [modalStatus, setModalStatus] = useState('closed');
const [modalMessage, setModalMessage] = useState('');
useEffect(() => {
(async function () {
setLoading(true);
fetchProducts()
.then((products) => {
setProductList(products);
setError(false);
})
.catch((error) => {
setError(error);
})
.finally(() => {
setLoading(false);
});
})();
}, []);
useEffect(() => {
setModalStatus('opened');
setModalMessage(error.message ?? '잠시 후 다시 시도해주세요.');
}, [error]);
useEffect(() => {
if (modalStatus !== 'closed') {
setTimeout(() => {
setModalStatus('closed');
setModalMessage('');
}, 1000);
}
}, [modalStatus]);
return (
<>
{productList.map((product) => (
<span key={product.name}>{product}</span>
))}
{modalStatus === 'opened' && <Modal>{modalMessage}</Modal>}
</Modal>
)
}
위 코드는 product 라는 문맥과 modal 이란 문맥이 관련된 로직이 섞여있습니다.
이를 리뷰하기 위해선 하나의 컴포넌트에서 다음과 같은 부분을 인지해야 합니다.
- product state 와 그에 의존하는 Side Effect 로직을 인지해야 합니다.
- modal state 와 그에 의존하는 Side Effect 로직을 인지해야 합니다.
- 컴포넌트에서 product, modal state 와 연관된 Rendering 로직을 인지해야 합니다.
이러한 문맥들을 훅으로 Chunking 하면 어떨까요?
function ProductListPage() {
// type Modal = {
// status: 'opened' | 'closed';
// message: string;
// open: (message: string) => void;
// }
const modal = useModal();
const {
data: productList,
loading,
error,
} = useProductList({
onError: (error) => {
modal.open(error.message ?? '잠시 후 다시 시도해주세요.');
},
});
return (
<>
{productList.map((product) => (
<span key={product.name}>{product}</span>
))}
{modal.status === 'opened' && <Modal>{modal.message}</Modal>}
</>
);
}
이젠 컴포넌트를 리뷰하기 위해선 단 하나, productList 와 modal 과 관련된 Rendering 로직을 리뷰하면 됩니다.
그리고 modal 과 관련된 로직은 useModal 에서, product 와 관련된 로직은 useProductList 에서 리뷰하면 되겠죠.
이런 식으로 특정 문맥과 관련된 로직들은 모듈로 구분해주면 코드를 볼 때나 유지보수 할 때 특정 문맥만 파악하면 되므로 편리합니다.
만약, 이런 훅들이 서로 의존성이 없다면 컴포넌트 단위 까지 분리해주면 re-render 범위도 줄어들어
보다 최적화된 컴포넌트를 만들어낼 수 있을 거예요.
폴더 구조
앞선 로직들을 폴더 구조로 표현한다면 어떤 식으로 만들어야 할까요? 이렇게 나눌 수 있지 않을까요?
ㄴ hooks
ㄴ useModal.ts
ㄴ useProductList.ts
ㄴ page
ㄴ product
ㄴ components
ㄴ ProductList.tsx
사실 정답은 없습니다만, 저는 hook 이란 문맥이 너무 많은 의미를 내포하고 있다고 생각합니다.
앞서 언급했던 useModal 은 공통적으로 사용할 수 있는 훅입니다. Modal 을 사용하는 컴포넌트는 어디서든 호출하여 사용할 수 있죠.
그러나, useProductList 는 Product 라는 제한된 문맥에서 사용할 수 있는 훅입니다.
이 공통적인 훅과, 특정 도메인에서 사용한다는 문맥을 구분해주면 어떨까요?
ㄴ common
ㄴ hooks
ㄴ useModal.ts
ㄴ page
ㄴ product
ㄴ components
ㄴ ProductList.tsx
ㄴ hooks
ㄴ useProductList.ts
useModal.ts 와 useProductList.ts 모듈의 위치 만으로 각 모듈이 어떤 문맥에서 사용되는지 파악할 수 있습니다. 이는 프로젝트 참여자가 보다 모듈의 사용처와 프로젝트 구조를 이해하기 쉽게 만들어준다고 생각합니다.